Pergunta difícil. Vamos mudar para: “qual é a estimação da propensão marginal a consumir no Brasil que se obtém com dados do IBGE, supondo que a função consumo seja a keynesiana acrescida da hipótese de que impactos da renda sobre o consumo são defasados no tempo”?
Ficou um pouco comprido, mas mais honesto e menos pretencioso, não? Além de nos possibilitar estimar a propensão marginal de curto prazo e dela extrair a de longo prazo. Ahhhh!!! Agora sim, né?
Vamos usar, então dados mensurados no tempo (séries de tempo ou, no original, time series). Tome-se o período de 1950-2012. Vamos, na verdade, replicar o exemplo 17.7 da última edição do livro de Gujarati & Porter para dados brasileiros. Basicamente é isto.
Coleta de Dados
Primeiramente, usei o IPEADATA para buscar dados correntes (ou seja, nominais) do PIB e do consumo final das famílias. Em seguida, obtive o deflator implícito do PIB e mudei sua base para 2012. Obtive os valores do PIB e do consumo a preços de 2012 e, claro, obtive a população residente do país e calculei os valores per capita.
Obviamente você poderá me dizer que eu deveria usar a renda e não o PIB. Outra crítica poderia ser para a medida de população. Enfim, é apenas um exercício e se você quiser me enviar os links para os dados, eu agradeço. De qualquer forma, após importar os dados para o R, assumi que existem infinitos efeitos de defasagem da renda sobre o consumo, o que significa que decidi estima uma forma funcional específica que está explicada de maneira muito didática na seção 17.4 do Gujarati.
Só para matar a curiosidade, veja os gráficos das duas séries.
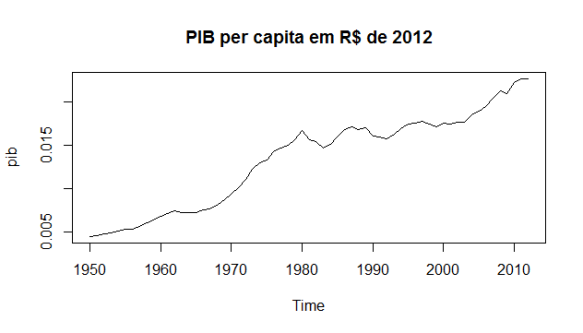
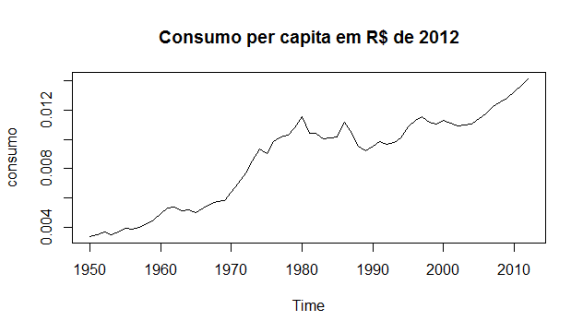
Bonito, né?
Veja bem, trata-se da função keynesiana mesmo, mas com defasagens. Digo isto porque meus alunos também aprendem outra função consumo que é a derivada da hipótese da renda permanente, cuja especificação é muito parecida, mas não idêntica à do exercício que estamos descrevendo aqui. Bem, o leitor que já passou pelas páginas do livro sabe que, neste caso, a função consumo que se obtém com alguma álgebra é:
Ct = a + bYt + cCt-1 + et
Assim, estimei esta função e obtive:
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.0005092 0.0001490 3.418 0.00115 **
pib[, 1] 0.2188254 0.0501393 4.364 5.21e-05 ***
cons[, 2] 0.6154625 0.0877814 7.011 2.59e-09 ***
—
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.0003554 on 59 degrees of freedom
Multiple R-squared: 0.9871, Adjusted R-squared: 0.9867
F-statistic: 2259 on 2 and 59 DF, p-value: < 2.2e-16
Em outras palavras, a equação estimada é:
Ct = 0.0005092 + 0.2188254Yt + 0.6154625Ct-1 + resíduos
Simples, não? Agora vamos falar do estado estacionário. No longo prazo, como sabemos, as variáveis estarão em seu estado estacionário e, obviamente, a média dos erros é zero. Usando a nossa estimação, isto significa que:
C = 0.0005092 + 0.2188254Y+ 0.6154625C
Obviamente:
C = [0.0005092 + 0.2188254Y] /[1 – 0.6154625 ]
C = 0.0013 + 0.5691Y
O que significa isto?
Significa que a propensão marginal a curto prazo (PMgCP) é, aproximadamente, 0.2188 e a de longo prazo é, aproximadamente, 0.5691. Ok, você pode me dizer que esperava uma PMgLP mais alta, próxima da unidade. Mas vamos ver mais algumas coisas neste exemplo antes de discutir este ponto.
Repare na defasagem mediana: – log(2)/log(0.6154625) = 1.428. Ela nos diz que 50% da mudança de uma unidade da renda leva cerca de 1.4 anos para fazer efeito no consumo. Claro, podemos calcular também a defasagem média, dada por: 0.6154625/(1-0.6154625) = 1.6005, ou seja, a defasagem média do efeito é de 1.6 anos.
Limitações?
Pois é. A PMgLP ficou um pouco acima da metade do que esperaríamos. Afinal, a teoria nos diz que a PMgLP deveria ser unitária. Ceteris paribus, podemos discutir um pouco isto.
No campo teórico, obviamente, você pode me dizer que este modelo é ruim porque não leva em conta as expectativas dos consumidores. Poderíamos rever isto simplesmente estimando a uma função consumo que incorporasse este aspecto importante. Não é difícil e a literatura nos dá duas famosas alternativas: o modelo de Friedman da renda permanente e o modelo de Hall (também chamado, muitas vezes, de modelo de renda permanente, mas com a ressalva que a hipótese sobre a formação de expectativas dos agentes é distinta da adotada por Friedman).
Empiricamente há ainda a chamada falácia ecológica que diz respeito ao fato de usarmos dados agregados – ainda que per capita – para falar de indivíduos. Em outras palavras, a base de dados deveria ser oriunda de algum estudo com microdados. Ok, esta é uma crítica importante, mas implicaria em partirmos para outro exemplo.
Ainda empiricamente, e de forma relacionada ao debate teórico, há a questão das propriedades que dados no tempo possuem (sazonalidade, tendência e se ambas são deterministas ou estocásticas). Esta é outra crítica importante e que não será tratada aqui porque, afinal, minha idéia foi só ajudar o leitor a aproveitar seu tempo de forma divertida.
Claro, não falamos de detalhes econométricos deste exercício, mas você já deve estar cansado de tanta emoção, não?
Dica do dia!
Agora vamos ao almoço quase gratuito de hoje: a rotina de R utilizada. Você, obviamente, precisa ter sua planilha salva em formato .csv antes de qualquer coisa. Eis uma imagem da minha.
Para o código em R:
# importar os dados
dados<-read.table("C:/Users/cdshi_000/Documents/Meus Documentos/Meus Documentos/cursos/Econometria ii/funcao_consumo_anual.csv",header=TRUE, sep=",", na.strings="NA", dec=".", strip.white=TRUE)
# informar ao R que são séries de tempo, começando em 1947, frequência anual
series <- ts(dados, start=c(1947), freq=1)
# checar cabeçalho para ver se não houve algum erro.
head(series)
# vamos trabalhar com uma janela da amostra.
blog<-window(series, start=c(1950), end =c(2012))
# ler colunas 8 e 7
consumo<-blog[,8]
pib<-blog[,7]
# grafico para, novamente, ver se não houve problema na leitura dos dados
plot(consumo, main="Consumo per capita em R$ de 2012")
plot(pib, main="PIB per capita em R$ de 2012")
# construindo a defasagem do consumo e do PIB (posso querer usá-lo depois (PIB)).
consumolag=lag(consumo,-1)
piblag= lag(pib, -1)
# criando a matriz com consumo e a defasagem do mesmo. Idem para pib
cons=ts.intersect(consumo, consumolag)
pib =ts.intersect(pib, piblag)
# resumo da regressao do exemplo 17.7 de Gujarati & Porter, com dados brasileiros
summary(lm(cons[,1]~pib[,1] + cons[,2]))
Repare que meu código é didaticamente explicado (o que não significa que você não tenha que fazer algum esforço, né?). Quantos resultados interessantes, não? Eu os levaria ao professor de Econometria I (no caso de nossa faculdade, o Marcio Salvato) ou a outros caras muito bons de Econometria (como o Ari, Reginaldo, Jonathan, Guilherme, para falar só de algumas referências ótimas que temos na faculdade).
Legal, não?

 Bem, eis as notas do gráfico:
Bem, eis as notas do gráfico:
 Bom, esta foi uma semana intensa. Tive que estar no VI Congresso da AMDE, nas salas de aula e na prévia do Nepom acompanhada de pizza e texto do Milton Friedman. Não pude fazer direito tudo, obviamente.
Bom, esta foi uma semana intensa. Tive que estar no VI Congresso da AMDE, nas salas de aula e na prévia do Nepom acompanhada de pizza e texto do Milton Friedman. Não pude fazer direito tudo, obviamente.


